From Zero to Hero: Scaling up to million users
Server | Database | Load Balancer | Database Replication | Cache | Content delivery network | Stateless Web Tier | Data centers | Cost & computing | Message Queue | Metrics | Database Scaling | 1 Million Users | Cost and Computing
Designing a system that supports millions of users is challenging, and it is a journey that requires continuous refinement and endless improvement. Let's investigate on what's the system that supports a single user and gradually scale it up to serve millions of users.
- The system that supports a single user is simple, but as the number of users increases, the system becomes more complex. The complexity arises from the need to handle multiple requests, manage data consistency, and ensure high availability.
- The system must be able to scale horizontally, meaning that it can add more servers to handle the increased load. This requires some planning and design to ensure that the it can handle the increased traffic without crashing or slowing down.
- The system must also be able to handle failures gracefully, meaning that if one server goes down, the system can continue to function without interruption. This requires redundancy and failover mechanisms to ensure that the system can recover quickly from failures.
After reading this article, you should have a good understanding of how to design and build a system that can handle millions of users. You should also be able to identify the challenges and trade-offs involved in building such a system, and how to overcome them.
A journey begins with a single step where everything is running on a single server: web app, database, cache, etc.
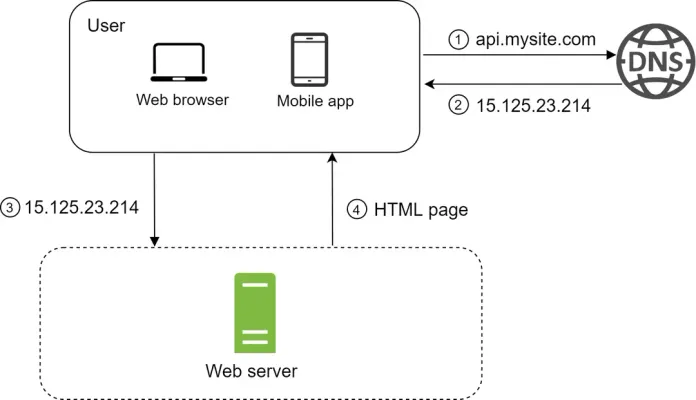
Let's investigate the request flow and traffic source!
- Users access websites through domain names, such as api.mysite.com. Usually, the Domain Name System (DNS) is a paid service provided by 3rd parties and not hosted by our servers.
- Internet Protocol (IP) address is returned to the browser or mobile app. In the example, IP address 15.125.23.214 is returned.
- Once the IP address is obtained, Hypertext Transfer Protocol (HTTP) 1 requests are sent directly to your web server.
- The web server returns HTML pages or JSON response for rendering.
// GET /users/12 - Retrieve user object for id = 12
{
"id":12,
"firstName":"John",
"lastName":"Smith",
"address":{
"streetAddress":"21 2nd Street",
"city":"New York",
"state":"NY",
"postalCode":10021
},
"phoneNumbers":[
"212 555-1234",
"646 555-4567"
]
}
Next, the traffic source. The traffic to the web server comes from two sources: web, mobile apps, and API.
- Web: It uses a combination of server-side languages (Java, Python, etc.) to handle business logic, storage, etc., and client-side languages (HTML and JavaScript) for presentation.
- Mobile: HTTP protocol is the communication protocol between the mobile app and the web server. JavaScript Object Notation (JSON) is commonly used API response format to transfer data due to its simplicity.
- API: The web server exposes a RESTful API that allows the mobile app to access the data. The API is designed to be stateless, meaning that each request from the client contains all the information needed to process the request.
With the growth of the user base, one server is not enough, and we need multiple servers: one for web/mobile traffic, the other for the database.
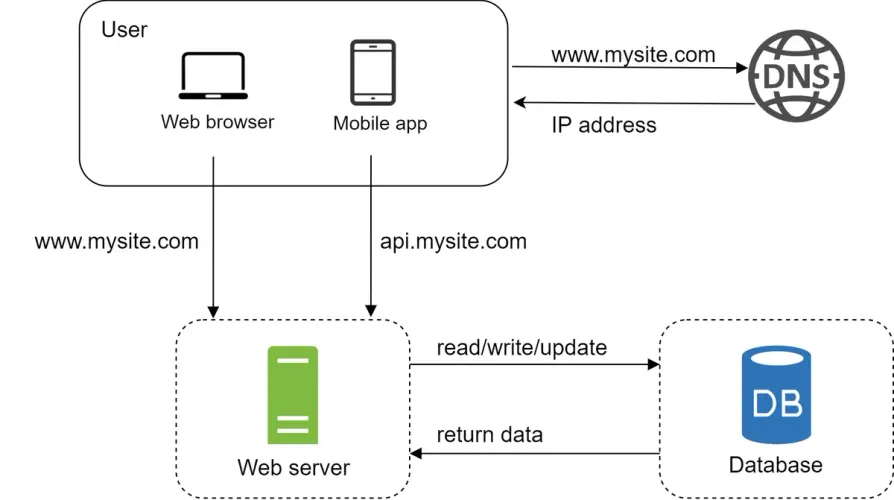
Separating web/mobile traffic (web tier) and database (data tier) servers allows them to be scaled independently. The web tier can be scaled horizontally by adding more web servers, while the data tier can be scaled vertically by upgrading the database server. This separation also allows for better performance and reliability, as each tier can be optimized for its specific workload.
Which databases to use?
- relational database
- or a non-relational database?
Relational Databases (RDBMS / SQL)
Relational databases store data in tables with rows and columns, using a fixed schema. They support complex join operations through SQL, making them ideal for structured data with well-defined relationships. They are best suited for apps with complex queries and transactions.
Popular relational databases:
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
Use cases include applications requiring strong consistency, ACID transactions, and structured schemas.
Non-Relational Databases (NoSQL)
Non-relational databases, or NoSQL databases, do not rely on fixed table-based schemas and are better suited for unstructured or semi-structured data. Most NoSQL databases do not support joins, making them more scalable but sometimes requiring data denormalization.
They are grouped into four main categories:
- Key-Value Stores: Redis, Amazon DynamoDB
- Document Stores: MongoDB, CouchDB
- Column Stores: Apache Cassandra, HBase
- Graph Stores: Neo4j
Use cases include scalability, flexible schema, high-throughput, and big data scenarios.
Vertical vs horizontal scaling
Vertical:
- Upgrade instance size: quick solution, but limited by hardware.
- Scale up: add CPU/RAM to one server.
- Simple for low traffic.
- Unlimited power, in theory.
- Limited by physical server capacity.
- No redundancy: one failure = full outage.
- Load balancer keeps users connected.
- Web server offline? Users can still access the site.
- Too many users? Responses slow or fail.
Horizontal:
- Add more instances: app containers, DB replicas.
- Horizontal scaling (“scale-out”): add servers to share load.
- Better for large apps: avoids vertical scaling limits.
- Improves traffic handling, failover, and redundancy.
- If one fails, others keep the app running.
- Without a load balancer, users hit servers directly.
- If a server is down, users can’t connect.
- Heavy traffic? Slower responses or connection failures.
- Use a load balancer to distribute traffic and avoid overload.
A load balancer evenly distributes incoming traffic among web servers that are defined in a load-balanced set. Users connect directly to the public IP of the load balancer. With this setup, web servers are no longer directly accessible by clients, which improves security. Internally, the load balancer communicates with web servers via private IP addresses - these are only reachable within the same network and are not accessible over the internet.
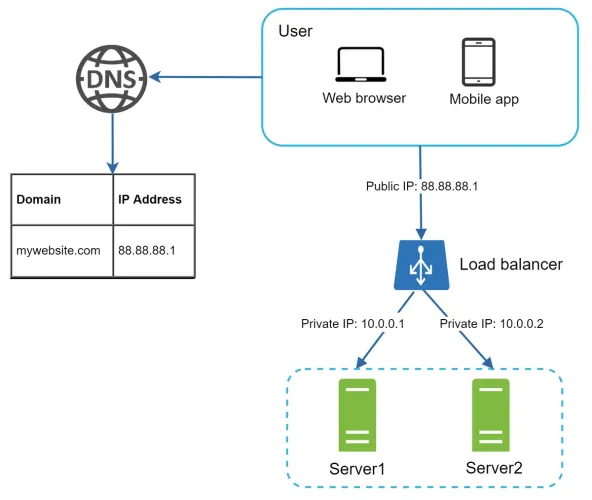
High Availability and Failover
By introducing a load balancer and a second web server, we've addressed the issue of no failover and significantly improved the availability of the web tier.
- Failover Handling
If Server 1 goes offline, the load balancer automatically routes all incoming traffic to Server 2, preventing downtime. - Elastic Scaling
If traffic increases and two servers are no longer sufficient, additional web servers can be added to the pool. The load balancer automatically distributes requests among healthy servers, ensuring continued performance and reliability. - Server Pool Health Checks
The load balancer continuously performs health checks and only forwards requests to healthy servers in the pool.
“Database replication can be used in many database management systems, usually with a master/slave relationship between the original (master) and the copies (slaves).”
- A master database generally only supports write operations.
- A slave database receives replicated data from the master and supports read operations only.
All data-modifying commands like INSERT, DELETE, or UPDATE must be sent to the master database. Most applications require a much higher ratio of reads to writes. Therefore, the number of slave databases in a system is typically greater than the number of master databases.
Advantages of Database Replication
- Better Performance:
In the master-slave model, all write and update operations occur on master nodes, while read operations are distributed across slave nodes. This setup improves performance by allowing more queries to be processed in parallel. - Reliability:
If one of your database servers is destroyed by a natural disaster, such as a typhoon or earthquake, data remains preserved. Replication ensures that data is stored across multiple locations, minimizing the risk of loss. - High Availability:
Replicating data across different servers allows the website to continue operating even if one database goes offline. Users can still access data from another functioning server.
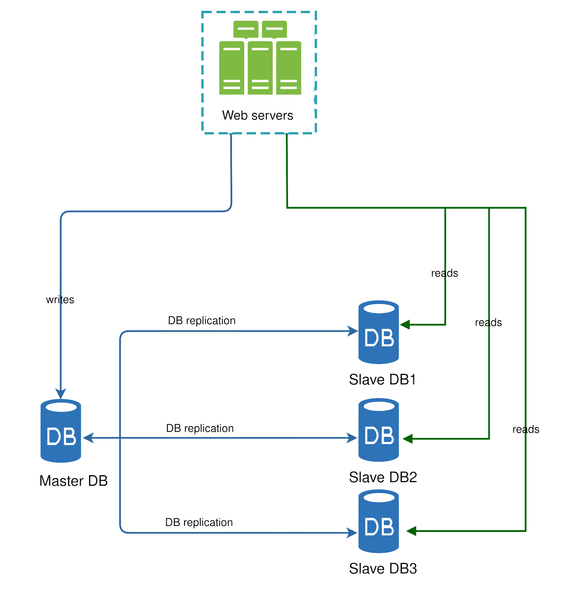
Handling Failures in Replication
In the previous section, we discussed how a load balancer improves system availability. We ask a similar question here: what if one of the databases goes offline?
The architecture in Figure 5 addresses this:
- If a single slave database goes offline:
Read operations are temporarily redirected to the master database.
A new slave database is then added to replace the failed one. - If multiple slave databases are available and one fails:
Read operations are redirected to other healthy slave databases.
The failed database is replaced with a new one. - If the master database goes offline:
A slave database is promoted to become the new master.
All database operations temporarily execute on the promoted node.
A new slave is added for replication purposes.
In production systems, promoting a new master is more complex.
The slave may not have the most recent data, requiring data recovery scripts to fill in the gaps.
Advanced methods like multi-master or circular replication can help but involve greater complexity, which is beyond the scope of this guide.
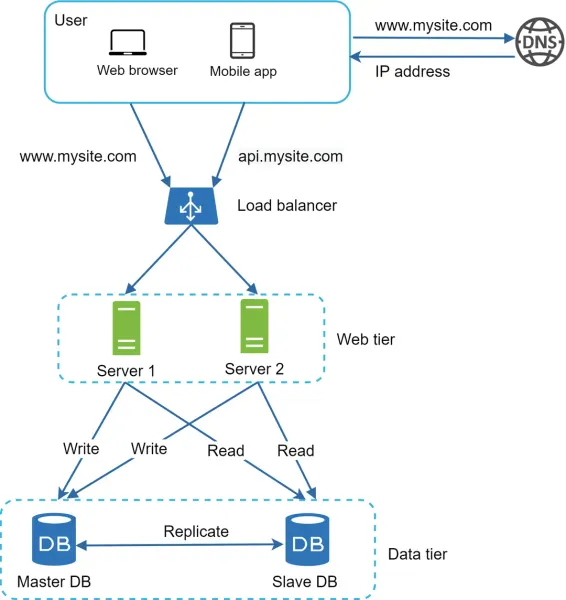
Architecture Request Flow
- The user obtains the load balancer’s IP address from DNS.
- The user sends an HTTP request to the load balancer using that IP address.
- The load balancer forwards the request to either Web Server 1 or Web Server 2.
- The web server retrieves user data from a read-only slave database.
- For write, update, or delete operations, the web server routes the request to the master database.
With a solid understanding of the web and data tiers, the next step is to enhance load and response times. This can be achieved by:
- Introducing a cache layer to reduce repeated database queries and speed up data access.
- Offloading static content — such as JavaScript, CSS, images, and videos — to a Content Delivery Network (CDN) for faster delivery and reduced server load.
A cache is a temporary storage layer that holds the results of expensive or frequently requested operations in memory. This allows subsequent requests to be served much faster. Loading a web page often triggers multiple database queries. Repeatedly querying the database can significantly degrade application performance. By storing commonly accessed data in a cache, we reduce the need for frequent database access and improve overall response time.
Cache Tier

After receiving a request, a web server first checks if the cache has the available response. If it has, it sends data back to the client. If not, it queries the database, stores the response in cache, and sends it back to the client.
This caching strategy is called a read-through cache. Other caching strategies are available depending on the data type, size, and access patterns.
Interacting with cache servers is simple because most cache servers provide APIs for common programming languages. The following code snippet shows typical Memcached APIs:
SECONDS = 1
cache.set('myKey, 'hi there', 3600 * SECONDS)
cache.get('myKey')
The cache tier is a high-speed, temporary data storage layer positioned between the application and the database. It serves frequently accessed or computationally expensive data, reducing the need to query the database repeatedly.
Benefits of a dedicated cache tier include:
- Faster performance – Data loads quicker from cache than DB.
- Lighter DB load – Fewer queries free the DB for key tasks.
- Scales independently – Cache can grow without touching DB.
- Cost savings – Cuts need for costly DB resources.
- Flexible tech – Use Redis, Memcached, or in-memory stores.
- Fault-tolerant – If cache fails, app still works via DB.
- Efficient scaling – Cache scales alone for better performance.
Considerations When Using a Cache System
Here are a few important factors to keep in mind when implementing a caching layer:
- When to Use Cache: Caching is ideal when data is read frequently but modified infrequently. Since cache data is stored in volatile memory, it is not suitable for persistent storage. For example, if a cache server restarts, all stored data is lost. Therefore, critical or persistent data should always be saved in a durable data store.
- Expiration Policy: Implementing an expiration policy is essential to manage memory efficiently. When cached data expires, it is removed from memory. Without expiration, cached items remain indefinitely, which can waste resources. A good expiration policy strikes a balance: Too short: Frequent reloads from the database, adding load and latency. Or Too long: Data may become stale or outdated.
- Data Consistency: Maintaining consistency between the cache and the data store is challenging. Since cache and database operations are often not performed in a single transaction, discrepancies may occur. This issue becomes more complex in distributed systems across multiple regions. For in-depth discussion, refer to the paper “Scaling Memcache at Facebook”.
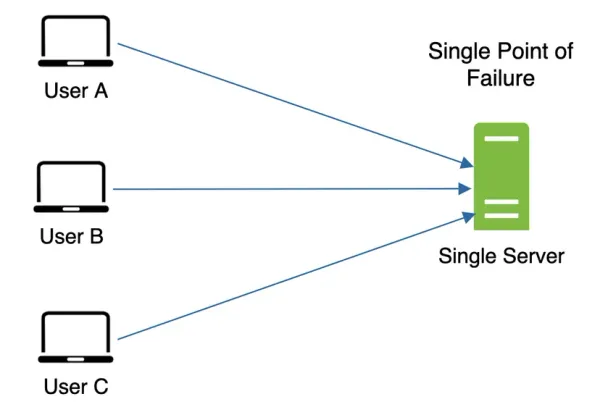
- Mitigating Failures: A single cache server introduces a Single Point of Failure (SPOF) - if it goes down, the entire system can be affected. To mitigate this risk: Deploy multiple cache servers across different data centers. Or Overprovision cache memory by a safety margin to account for growth or unexpected spikes.
- Eviction Policy: When the cache is full, older or less important items must be removed to make space. This process is known as cache eviction. Common eviction policies include: LRU (Least Recently Used) – Removes items that haven’t been accessed recently. LFU (Least Frequently Used) – Removes items accessed the least. FIFO (First In, First Out) – Removes items in the order they were added.
Content delivery network - CDN
A CDN is a network of geographically dispersed servers used to deliver static content. CDN servers cache static content like images, videos, CSS, JavaScript files, etc.

Dynamic content caching is a relatively new concept and beyond the scope of this course. It enables the caching of HTML pages that are based on request path, query strings, cookies, and request headers. Refer to the article mentioned in reference material 9 for more about this. This course focuses on how to use CDN to cache static content.
Here is how CDN works at the high-level: when a user visits a website, a CDN server closest to the user will deliver static content. Intuitively, the further users are from CDN servers, the slower the website loads. For example, if CDN servers are in San Francisco, users in Los Angeles will get content faster than users in Europe.
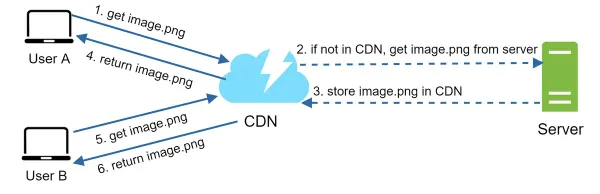
- User A tries to get image.png by using an image URL. The URL’s domain is provided by the CDN provider. The following two image URLs are samples used to demonstrate what image URLs look like on Amazon and Akamai CDNs:
{kind=link}
{kind=link}
- If the CDN server does not have image.png in the cache, the CDN server requests the file from the origin, which can be a web server or online storage like Amazon S3.
- The origin returns image.png to the CDN server, which includes optional HTTP header Time-to-Live (TTL) which describes how long the image is cached.
- The CDN caches the image and returns it to User A. The image remains cached in the CDN until the TTL expires.
- User B sends a request to get the same image.
- The image is returned from the cache as long as the TTL has not expired.
::
When to CDN ?
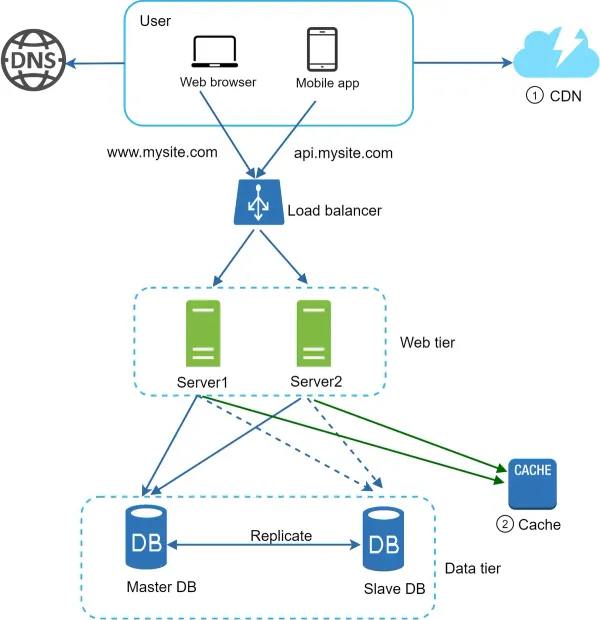
- Static assets (JS, CSS, images, etc.,) are no longer served by web servers. They are fetched from the CDN for better performance.
- The database load is lightened by caching data.
- Cost: CDNs are run by third-party providers, and you are charged for data transfers in and out of the CDN. Caching infrequently used assets provides no significant benefits so you should consider moving them out of the CDN.
- Setting an appropriate cache expiry: For time-sensitive content, setting a cache expiry time is important. The cache expiry time should neither be too long nor too short. If it is too long, the content might no longer be fresh. If it is too short, it can cause repeat reloading of content from origin servers to the CDN.
- CDN fallback: You should consider how your website/application copes with CDN failure. If there is a temporary CDN outage, clients should be able to detect the problem and request resources from the origin.
- Invalidating files: You can remove a file from the CDN before it expires by performing one of the following operations:
- Invalidate the CDN object using APIs provided by CDN vendors.
- Use object versioning to serve a different version of the object. To version an object, you can add a parameter to the URL, such as a version number. For example, version number 2 is added to the query string: image.png?v=2. Design after the CDN and cache are added.
Now it is time to consider scaling the web tier horizontally. For this, we need to move state (for instance user session data) out of the web tier. A good practice is to store session data in the persistent storage such as relational database or NoSQL. Each web server in the cluster can access state data from databases. This is called stateless web tier.
Stateful architecture
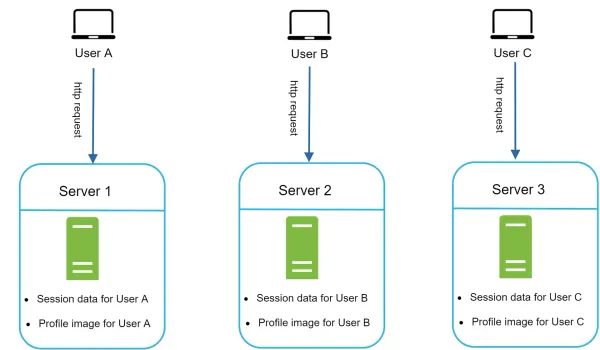
A stateful server and stateless server has some key differences. A stateful server remembers client data (state) from one request to the next. A stateless server keeps no state information.
User A’s session data and profile image are stored in Server 1. To authenticate User A, HTTP requests must be routed to Server 1. If a request is sent to other servers like Server 2, authentication would fail because Server 2 does not contain User A’s session data. Similarly, all HTTP requests from User B must be routed to Server 2; all requests from User C must be sent to Server 3.
The issue is that every request from the same client must be routed to the same server. This can be done with sticky sessions in most load balancers 10; however, this adds the overhead. Adding or removing servers is much more difficult with this approach. It is also challenging to handle server failures.
Stateless architecture
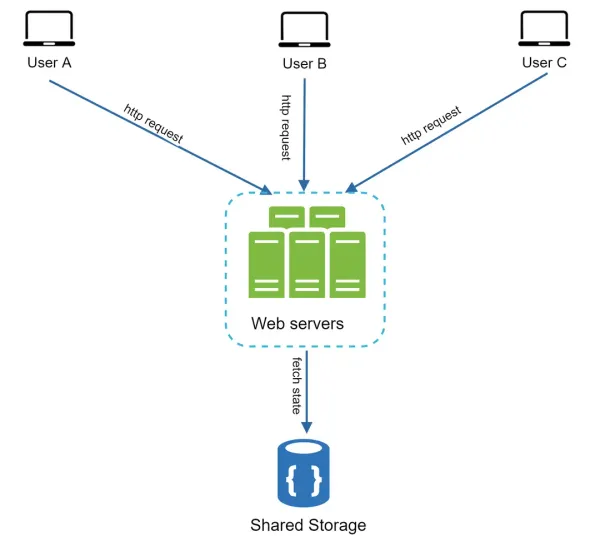
In this stateless architecture, HTTP requests from users can be sent to any web servers, which fetch state data from a shared data store. State data is stored in a shared data store and kept out of web servers. A stateless system is simpler, more robust, and scalable.
Stateless architecture: Updated design
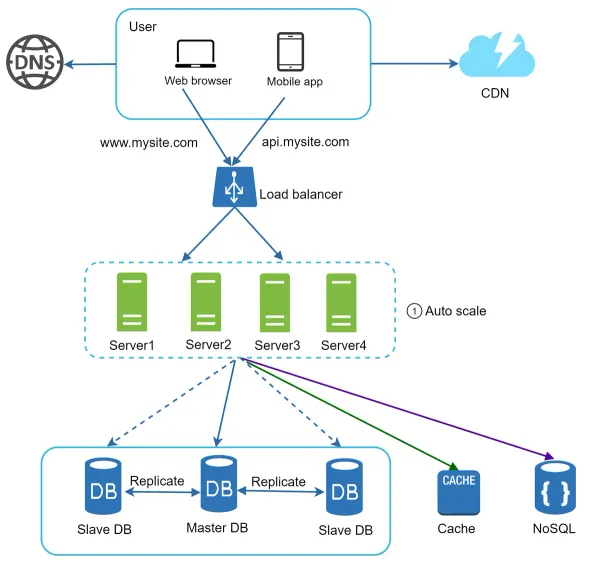
Here, we move the session data out of the web tier and store them in the persistent data store. The shared data store could be a relational database, Memcached/Redis, NoSQL, etc. The NoSQL data store is chosen as it is easy to scale. Autoscaling means adding or removing web servers automatically based on the traffic load. After the state data is removed out of web servers, auto-scaling of the web tier is easily achieved by adding or removing servers based on traffic load.
Your website grows rapidly and attracts a significant number of users internationally. To improve availability and provide a better user experience across wider geographical areas, supporting multiple data centers is crucial.
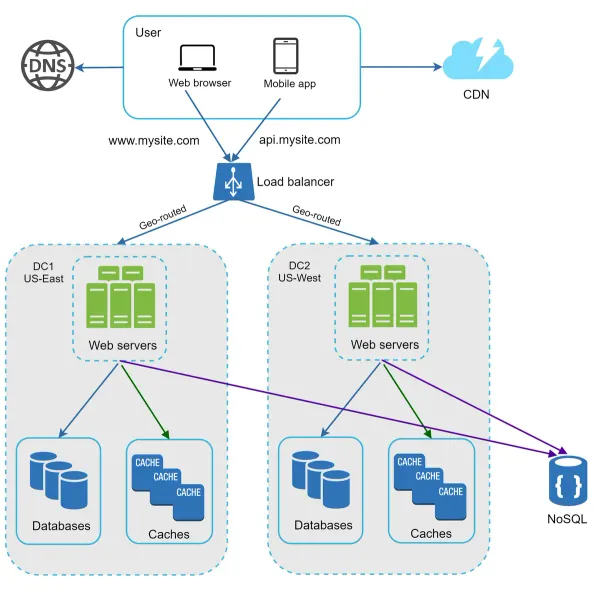
This is an example setup with two data centers. In normal operation, users are geoDNS-routed, also known as geo-routed, to the closest data center, with a split traffic of x% in US-East and (100 – x)% in US-West. geoDNS is a DNS service that allows domain names to be resolved to IP addresses based on the location of a user.
In the event of any significant data center outage, we direct all traffic to a healthy data center. In Figure 16, data center 2 (US-West) is offline, and 100% of the traffic is routed to data center 1 (US-East).
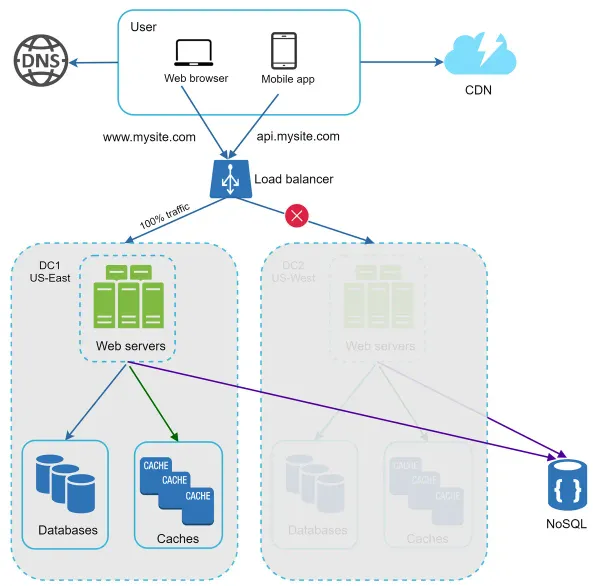
Several technical challenges must be resolved to achieve multi-data center setup:
- Traffic redirection: Effective tools are needed to direct traffic to the correct data center. GeoDNS can be used to direct traffic to the nearest data center depending on where a user is located.
- Data synchronization: Users from different regions could use different local databases or caches. In failover cases, traffic might be routed to a data center where data is unavailable. A common strategy is to replicate data across multiple data centers. A previous study shows how Netflix implements asynchronous multi-data center replication 11.
- Test and deployment: With multi-data center setup, it is important to test your website/application at different locations. Automated deployment tools are vital to keep services consistent through all the data centers 11.
To further scale our system, we need to decouple different components of the system so they can be scaled independently. Messaging queue is a key strategy employed by many real-world distributed systems to solve this problem.

A message queue is a durable component, stored in memory, that supports asynchronous communication. It serves as a buffer and distributes asynchronous requests. The basic architecture of a message queue is simple. Input services, called producers/publishers, create messages, and publish them to a message queue. Other services or servers, called consumers/subscribers, connect to the queue, and perform actions defined by the messages.
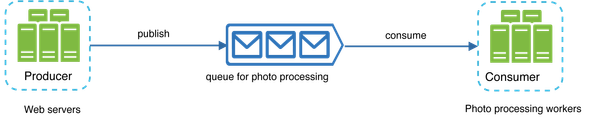
Decoupling makes the message queue a preferred architecture for building a scalable and reliable application. With the message queue, the producer can post a message to the queue when the consumer is unavailable to process it. The consumer can read messages from the queue even when the producer is unavailable.
Web servers publish photo processing jobs to the message queue. Photo processing workers pick up jobs from the message queue and asynchronously perform photo customization tasks. The producer and the consumer can be scaled independently. When the size of the queue becomes large, more workers are added to reduce the processing time. However, if the queue is empty most of the time, the number of workers can be reduced.
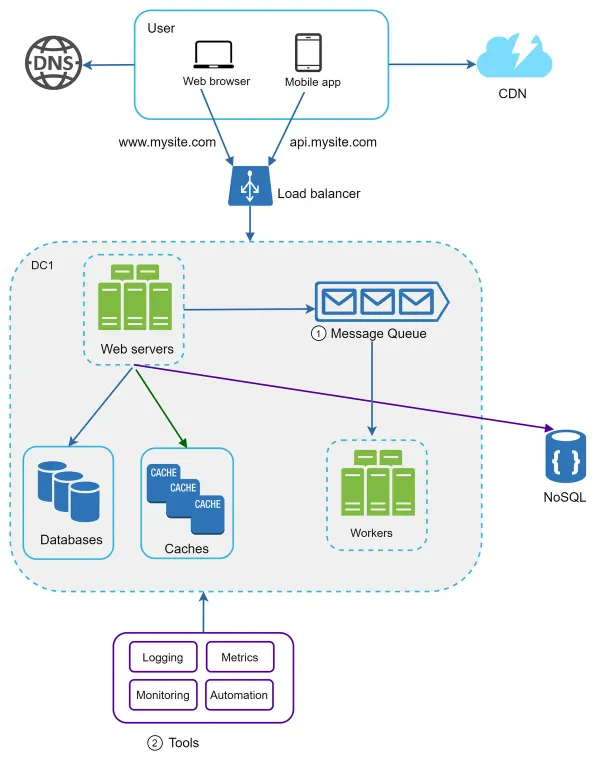
When working with a small website that runs on a few servers, logging, metrics, and automation support are good practices but not a necessity. However, now that your site has grown to serve a large business, investing in those tools is essential.
- Logging: Monitoring error logs is important because it helps to identify errors and problems in the system. You can monitor error logs at per server level or use tools to aggregate them to a centralized service for easy search and viewing.
- Metrics: Collecting different types of metrics help us to gain business insights and understand the health status of the system. Some of the following metrics are useful:
- Host level metrics: CPU, Memory, disk I/O, etc.
- Aggregated level metrics: for example, the performance of the entire database tier, cache tier, etc
- Key business metrics: daily active users, retention, revenue, etc.
- Automation: When a system gets big and complex, we need to build or leverage automation tools to improve productivity. Continuous integration is a good practice, in which each code check-in is verified through automation, allowing teams to detect problems early. Besides, automating your build, test, deploy process, etc. could improve developer productivity significantly.
Due to the space constraint, only one data center is shown in the figure.
- The design includes a message queue, which helps to make the system more loosely coupled and failure resilient.
- Logging, monitoring, metrics, and automation tools are included.
As the data grows every day, your database gets more overloaded. It is time to scale the data tier.
There are two broad approaches for database scaling: vertical scaling and horizontal scaling.
Vertical scaling
Vertical scaling, also known as scaling up, is the scaling by adding more power (CPU, RAM, DISK, etc.) to an existing machine. There are some powerful database servers. According to Amazon Relational Database Service (RDS) 12, you can get a database server with 24 TB of RAM. This kind of powerful database server could store and handle lots of data. For example, stackoverflow.com in 2013 had over 10 million monthly unique visitors, but it only had 1 master database 13. However, vertical scaling comes with some serious drawbacks:
- You can add more CPU, RAM, etc. to your database server, but there are hardware limits. If you have a large user base, a single server is not enough.
- Greater risk of single point of failures.
- The overall cost of vertical scaling is high. Powerful servers are much more expensive.
Horizontal scaling
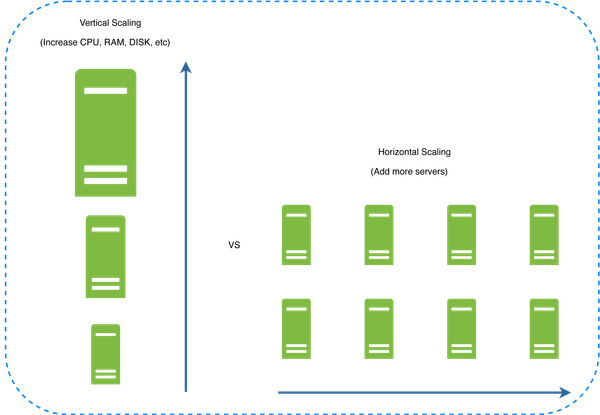
Horizontal scaling, also known as sharding, is the practice of adding more servers. Figure 20 compares vertical scaling with horizontal scaling.
Sharding separates large databases into smaller, more easily managed parts called shards. Each shard shares the same schema, though the actual data on each shard is unique to the shard.
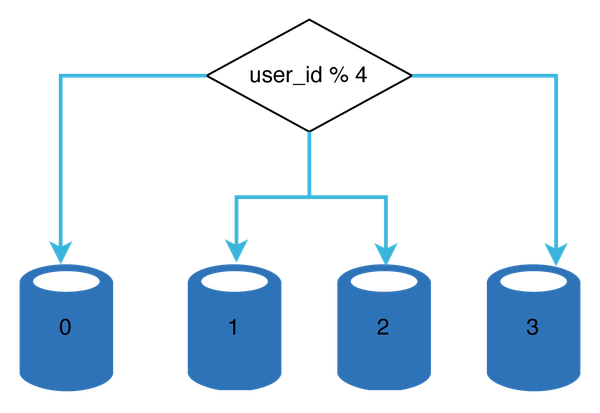
User data is allocated to a database server based on user IDs. Anytime you access data, a hash function is used to find the corresponding shard. In our example, user_id % 4 is used as the hash function. If the result equals to 0, shard 0 is used to store and fetch data. If the result equals to 1, shard 1 is used. The same logic applies to other shards.
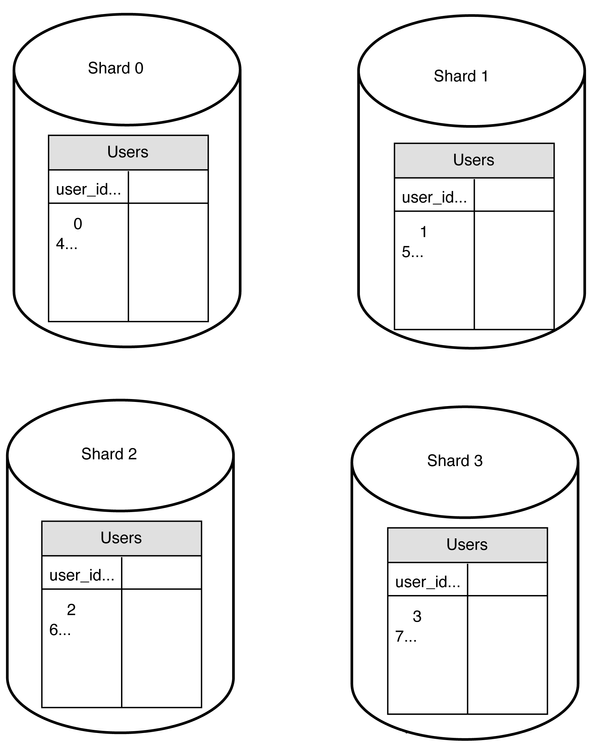
The most important factor to consider when implementing a sharding strategy is the choice of the sharding key. Sharding key (known as a partition key) consists of one or more columns that determine how data is distributed. As shown in Figure 22, “user_id” is the sharding key. A sharding key allows you to retrieve and modify data efficiently by routing database queries to the correct database. When choosing a sharding key, one of the most important criteria is to choose a key that can evenly distributed data.
Sharding is a great technique to scale the database but it is far from a perfect solution. It introduces complexities and new challenges to the system:
- Resharding data: Resharding data is needed when 1) a single shard could no longer hold more data due to rapid growth. 2) Certain shards might experience shard exhaustion faster than others due to uneven data distribution. When shard exhaustion happens, it requires updating the sharding function and moving data around. Consistent hashing is a commonly used technique to solve this problem.
- Celebrity problem: This is also called a hotspot key problem. Excessive access to a specific shard could cause server overload. Imagine data for Katy Perry, Justin Bieber, and Lady Gaga all end up on the same shard. For social applications, that shard will be overwhelmed with read operations. To solve this problem, we may need to allocate a shard for each celebrity. Each shard might even require further partition.
- Join and de-normalization: Once a database has been sharded across multiple servers, it is hard to perform join operations across database shards. A common workaround is to de-normalize the database so that queries can be performed in a single table.
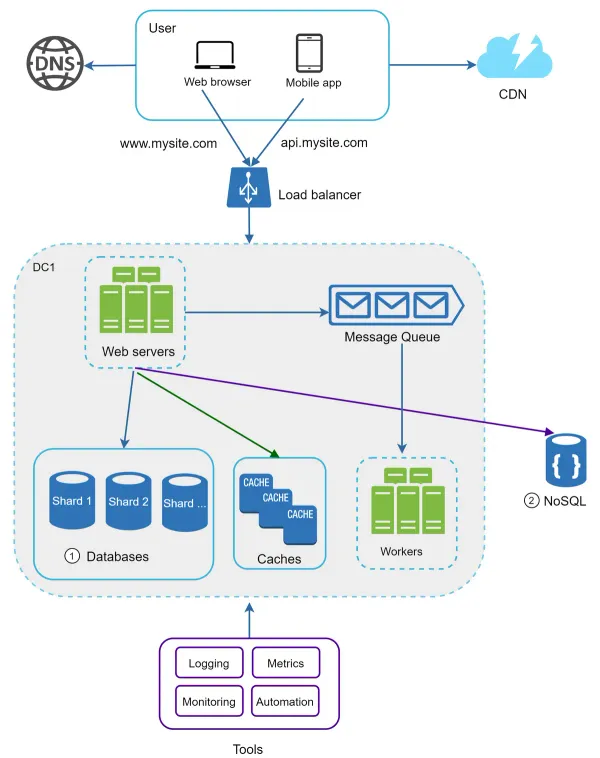
Here we shard databases to support rapidly increasing data traffic. At the same time, some of the non-relational functionalities are moved to a NoSQL data store to reduce the database load. Here is an article that covers many use cases of nosql
Scaling a system is an ongoing journey. The strategies in this chapter provide a solid foundation, but scaling beyond millions of users will require deeper optimizations and more modular architecture. You may need to decouple services further and fine-tune each tier. Here's a practical checklist for scaling to millions:
Scaling Checklist
- Keep the web tier stateless
- Add redundancy at every tier
- Cache as much as possible
- Support multiple data centers
- Serve static assets via a CDN
- Scale your data tier using sharding
- Split tiers into independent services
- Monitor systems and automate workflows
Congratulations on making it this far — you’ve built the foundation to scale! 🎉
With the growth of the user base, one server is not enough. We need multiple servers: one for web/mobile traffic (web tier), and the other for the database (data tier). This separation allows independent scalability.
Architecture
Two-Tier Architecture:
- Web Tier: Handles frontend, backend APIs, static content
- Data Tier: Stores user data and supports transactional operations
Cost Assumptions
Traffic
| Starter Tier | Growing App Tier | |
|---|---|---|
| Users/month | 1,000–5,000 | 10,000–100,000 |
| Requests/day | ~20,000 | ~200,000–500,000 |
| Stored Data | <5 GB | 50–200 GB |
AWS EC2 + Load Balancer + Storage
| Item | Starter | Growing |
|---|---|---|
| EC2 Instance Type | t3.micro (1GB RAM) | t3.medium / t3.large |
| Instances | 1 | 2–4 |
| EC2 Monthly Cost | $10–$15 | $60–$200 |
| Load Balancer | Optional | ~$18–$25 |
| EBS Storage | 50 GB (~$5) | 50–100 GB (~$10) |
| Web Tier Total | ~$20–30 | ~$80–250 |
Database Tier (AWS RDS)
| Item | Starter | Growing |
|---|---|---|
| DB Type | db.t3.micro | db.t3.medium / db.m5.large |
| Storage (SSD) | 20 GB | 100–200 GB |
| Automated Backups | Enabled | Enabled |
| Multi-AZ | Optional | Recommended |
| RDS Monthly Cost | ~$20–$30 | ~$100–250 |
Optional Services
| Service | Monthly Cost Estimate |
|---|---|
| Cloudflare CDN | Free – $20 |
| S3 Static Assets | ~$5–20 |
| Monitoring Tool | ~$0–50 |
Estimated Total Monthly Cost
| Tier | Starter Tier | Growing App Tier |
|---|---|---|
| Web Tier | $20–30 | $80–250 |
| Database Tier | $20–30 | $100–250 |
| Infra / Extras | $5–40 | $20–80 |
| Total | ~$50–100 | ~$200–580 |
Web Tier (EC2 or Container-Based)
t3.microort3.mediumare burstable — good for development/testing and up to ~100 concurrent users.t3.largeorm5.largescale better: ~2–4 vCPUs and 8 GB RAM handle 500–1,000 concurrent requests with caching.- Add an Elastic Load Balancer (ELB) to distribute traffic across multiple instances — can handle millions of requests/day.
- For auto-scaling, consider ECS (Fargate) or EKS (Kubernetes).
- Use Nginx or Cloudflare for static asset caching and DDoS protection.
- Add Redis for session/data caching — improves response times by 5–10×.
Database Tier (RDS or Managed DB)
t3.microRDS handles light DB queries (hundreds/min).t3.medium–m5.large: ~1,000–5,000 queries/sec for read-heavy workloads.- Use read replicas and PgBouncer (connection pooling) for scalability.
- Apply proper indexing, query optimization, and partitioning for large datasets.
Performance Estimates by Tier
| Tier | Instance Type | Req/sec | Avg Latency | Best For |
|---|---|---|---|---|
| Web (EC2) | t3.micro | ~10–20 | ~500ms | Development & testing |
| Web (EC2) | t3.medium | ~100–300 | ~150–300ms | Small production apps |
| Web (ECS/EKS) | Auto-scaled | ~1,000+ | <100ms | Medium–high traffic apps |
| DB (RDS) | t3.micro | ~100–200 | ~100ms | Small dev database |
| DB (RDS) | m5.large | ~1,000–5,000 | ~20–50ms | Scalable production database |
Tips: Performance
- CDN: Use Cloudflare, CloudFront, or S3 for fast delivery of static assets.
- Caching: Add Redis or Memcached for sessions, API responses, and heavy queries.
- Database Tuning: Use indexes, optimize queries, avoid N+1 queries.
- Lazy Loading: Defer loading of non-critical frontend resources.
- API Gateway: Improve observability, security, and request throttling.
Tips: Scaling
Monitoring & Observability
- Use auto-scaling groups for the web tier
- Add read replicas and caching (Redis) for the DBdat
- Consider serverless for on-demand workloads
- Enable CloudWatch, DataDog, or Sentry for monitoring
Recommended Actions
- Set up auto-scaling on API tier (target CPU: 60%).
- Enable CloudWatch Alarms for slow queries and error rate >1%.
- Add read replica monitoring for database scaling.
- Review cost optimizations monthly.
Review Checklist
- CPU usage < 70%
- Network usage < 75%
- Memory usage < 75%
- Response time < 200ms
- Error rate < 0.5%
- DB QPS < 75% of limit
- Budget < $300/month
Credits: Thank you to ByteByteGo for sharing their knowledge and experience in building scalable systems.
MCP Servers: Integrating LLM in E-Commerce Systems
A practical guide to evolving from static AI chat to dynamic, tool-augmented large language model integration across e-commerce architectures.
Quality: How to protect AI-powered Frontends?
Toda, AI isn’t just limited to specialized projects — it’s baked into almost everything we build. Whether it’s a search feature, a recommendation engine, a chatbot, or a predictive dashboard, AI is becoming a standard part of the stack.
MCP Servers: Integrating LLM in E-Commerce Systems
A practical guide to evolving from static AI chat to dynamic, tool-augmented large language model integration across e-commerce architectures.
Quality: How to protect AI-powered Frontends?
Toda, AI isn’t just limited to specialized projects — it’s baked into almost everything we build. Whether it’s a search feature, a recommendation engine, a chatbot, or a predictive dashboard, AI is becoming a standard part of the stack.